哈希表
哈希表
基础
哈希表
- 建立 key-value 映射;
- 在 O(1) 时间查找;
时间复杂度
| 时间复杂度 | |
|---|---|
| 查找 | 1 |
| 插入 | 1 |
| 删除 | 1 |
哈希算法
哈希算法的目标
- 确定性;
- 效率高;
- 平均分布;
应用领域
- 密码存储;
- 数据完整性检查;
安全标准
- 抗碰撞性;
- 雪崩效应;
常用的哈希算法
| MD5 | SHA-1 | SHA-2 | SHA-3 | |
|---|---|---|---|---|
| 推出时间 | 1992 | 1995 | 2002 | 2008 |
| 输出长度 | 128 bits | 160 bits | 256 / 512 bits | 224/256/384/512 bits |
| 哈希冲突 | 较多 | 较多 | 很少 | 很少 |
| 安全等级 | 低, 已被成功攻击 | 低, 已被成功攻击 | 高 | 高 |
| 应用 | 已被弃用, 仍用于数据完整性检查 | 已被弃用 | 加密货币交易验证, 数字签名等 | 可用于替代 SHA-2 |
数组实现
数组
- 数组的每一个空位称作桶;
- 一个桶存储一个键值对;
哈希函数
- 将一个较大的输入空间映射到较小的输出空间;
- 哈希表中即将 key 映射到 index;
哈希计算
- 通过哈希函数得到哈希值;
- 基于哈希值对数组长度取模;
index = hash(key) % capacity
哈希冲突和哈希扩容
基础
哈希冲突
- 多个输入对应相同输出;
哈希扩容
- 减少哈希冲突;
- 哈希表扩容计算开销极大;
- 尽量预留足够大的哈希表容量;
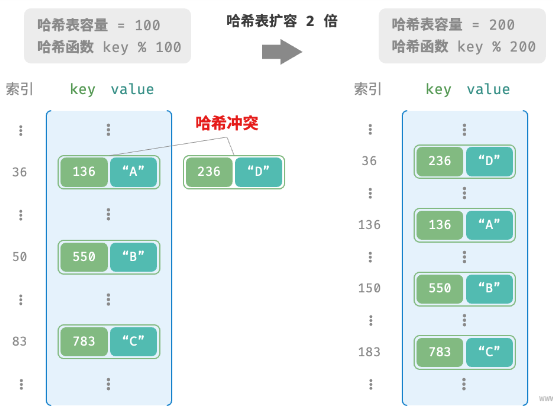
负载因子
- 哈希表元素数量 / 桶数量;
- 当达到负载因子时,触发哈希扩容;
- 简单的扩容策略;
- 负载因子到达 0.75,哈希表容量乘 2;
链式地址
链式地址
- 数组存储一个链表节点;
- 哈希冲突的键值对存储在同一链表中;
缺点
- 占用空间大;
- 查询效率低;
开放寻址
线性探测
插入元素
- 获取数组索引后,若桶已存在元素;
- 根据设置步长向后线性遍历直至找到空位;
查找元素
- 若哈希冲突;
- 向后线性遍历直至找到元素;
- 若遇到空位,则不存在哈希表中;
删除元素
- 不能直接删除元素;
- 需要使用一个标识位表示空位;
多次哈希
多次哈希
- 使用多个哈希函数;
- 若出现哈希冲突,使用下一个哈希函数;
代码实现(基于链式地址)
import { DoublyLinkedList } from "../linked_list/doubly_linked_list";
import { DoublyLinkedListNode } from "../linked_list/doubly_linked_list_node";
interface HashTableInterface {
key: string;
value: unknown;
}
export class HashTable {
bucket: DoublyLinkedList<HashTableInterface>[];
capacity: number;
constructor(capacity = 32) {
this.bucket = new Array(capacity).fill(1).map(() => new DoublyLinkedList());
this.capacity = capacity;
}
hash(key: string) {
let hash = 0;
const length = key.length;
for (let index = 0; index < length; index++) {
hash = hash * 31 + key.charCodeAt(index);
}
return hash % this.capacity;
}
set(key: string, value: unknown) {
const index = this.hash(key);
const linkedList = this.bucket[index];
const result = linkedList.find({ key, value }, (object: object) => {
const o = object as HashTableInterface;
if (o.key === key) return true;
else return false;
});
if (result) {
result.value = { key, value };
} else {
const node = new DoublyLinkedListNode({ key, value });
linkedList.insert(node, linkedList.head);
}
}
get(key: string) {
const index = this.hash(key);
const linkedList = this.bucket[index];
const result = linkedList.find(
{ key } as HashTableInterface,
(object: object) => {
const o = object as HashTableInterface;
if (o.key === key) return true;
else return false;
}
);
if (result) {
return result.value.value;
} else {
return null;
}
}
delete(key: string) {
const index = this.hash(key);
const linkedList = this.bucket[index];
const result = linkedList.find(
{ key } as HashTableInterface,
(object: object) => {
const o = object as HashTableInterface;
if (o.key === key) return true;
else return false;
}
);
if (result) {
linkedList.delete(result);
return result.value;
} else {
return null;
}
}
has(key: string) {
const index = this.hash(key);
const linkedList = this.bucket[index];
const result = linkedList.find(
{ key } as HashTableInterface,
(object: object) => {
const o = object as HashTableInterface;
if (o.key === key) return true;
else return false;
}
);
if (result) {
return true;
} else {
return false;
}
}
keys() {
const keys = [];
for (let index = 0; index < this.capacity; index++) {
const linkedList = this.bucket[index];
let currentNode: DoublyLinkedListNode<HashTableInterface> | null =
linkedList.head.next;
while (currentNode) {
keys.push(currentNode.value.key);
currentNode = currentNode.next;
}
}
return keys;
}
values() {
const values = [];
for (let index = 0; index < this.capacity; index++) {
const linkedList = this.bucket[index];
let currentNode: DoublyLinkedListNode<HashTableInterface> | null =
linkedList.head.next;
while (currentNode) {
values.push(currentNode.value.value);
currentNode = currentNode.next;
}
}
return values;
}
entries() {
const entries = [];
for (let index = 0; index < this.capacity; index++) {
const linkedList = this.bucket[index];
let currentNode: DoublyLinkedListNode<HashTableInterface> | null =
linkedList.head.next;
while (currentNode) {
entries.push([currentNode.value.key, currentNode.value.value]);
currentNode = currentNode.next;
}
}
return entries;
}
}
哈希表题目
多数元素
问题
- 169;
思路
- 遍历数组,建立哈希表,统计每个元素个数;
- 遍历哈希表,找出个数最多的元素;
/**
* @param {number[]} nums
* @return {number}
*/
var majorityElement = function (nums) {
const map = {};
let res = [];
for (const num of nums) {
if (map[num] != null) {
map[num]++;
} else {
map[num] = 1;
}
}
for (const num of nums) {
if (map[num] > Math.floor(nums.length / 2)) {
return num;
}
}
};
复杂度
- 时间/空间:n;
两数之和
题目
- 001;
思路
- 遍历数组,使用哈希表记录 target - num;
- 首先查找字典是否存在 target-num,存在返回对应下标和当前下标;
- 不存在添加 num;
- 假设 a + b = target;
- 第一次遇到 a,添加 target -a;
- 遇到 b,a 已经存在;
- 只需一次遍历即可;
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function (nums, target) {
const map = {};
for (let i = 0; i < nums.length; i++) {
const num = nums[i];
const sub = target - num;
if (map[sub] != null) {
return [map[sub], i];
} else {
map[num] = i;
}
}
};
复杂度
- 时间:n;
- 空间:n;
缺失的第一个正数
题目
- 41;
思路
- 视当前数组为一个哈希表;
- hash[i]存储 i+1;
- 首先遍历数组,将所有符合条件的正数交换到对应位置上;
- 正数在 1 - n;
- 当前位置数字不正确;
- 如果当前位置和目标位置元素相等,手动遍历下一个元素,避免无限循环;
- 其次遍历数组,找到第一个 hash[i] != i + 1 的元素,即第一个缺失的正数;
- 都满足返回 n + 1;
/**
* @param {number[]} nums
* @return {number}
*/
var firstMissingPositive = function (nums) {
let cur = 0;
while (cur < nums.length) {
const num = nums[cur];
if (num >= 1 && num <= nums.length) {
const target = num - 1;
[nums[cur], nums[target]] = [nums[target], nums[cur]];
if (num === nums[cur]) cur++;
} else {
cur++;
}
}
for (let i = 0; i < nums.length; i++) {
if (nums[i] !== i + 1) return i + 1;
}
return nums.length + 1;
};
复杂度
- 时间:n;
- 空间:1;
最长连续序列
题目
- 128;
思路
- 使用集合进行去重;
- 使用 cur 维护当前长度,res 维护最长连续序列长度;
- 遍历集合;
- 如果 num - 1,不在集合中,说明是序列的开始;
- 反之更新当前长度;
/**
* @param {number[]} nums
* @return {number}
*/
var longestConsecutive = function (nums) {
let res = 0;
let hash = new Set(nums);
for (let num of hash) {
if (!hash.has(num - 1)) {
let temp = 1;
while (hash.has(num + 1)) {
num++;
temp++;
}
res = Math.max(res, temp);
}
}
return res;
};
复杂度
- 时间:n;
- 空间:n;
字母异位词分组
题目
- 49;
思路
- 字母异位词字符串排序后相同;
- 使用一个哈希表,排序后的字母异位词作为 key,原始字母异位词作为 value;
/**
* @param {string[]} strs
* @return {string[][]}
*/
var groupAnagrams = function (strs) {
const hash = {};
for (const ch of strs) {
const temp = ch.split("").sort().join("");
if (hash[temp] == null) {
hash[temp] = [ch];
} else {
hash[temp].push(ch);
}
}
const res = [];
for (const value of Object.values(hash)) {
res.push(value);
}
return res;
};
复杂度
- 时间:n;
- 空间:n;
有效的字母异位词
题目
- 242;
思路
- 首先判断两者长度,不同返回 false;
- 遍历 s,哈希表存储字符出现数量;
- 遍历 t,减去对应字符出现数量;
- 小于 0,返回 false;
- 字符不存在,返回 false;
- 依旧存在大于 0 的字符,返回 false;
- 其余返回 true;
/**
* @param {string} s
* @param {string} t
* @return {boolean}
*/
var isAnagram = function (s, t) {
if (s.length !== t.length) return false;
const hash = {};
for (const ch of s) {
if (hash[ch]) hash[ch]++;
else hash[ch] = 1;
}
for (const ch of t) {
if (hash[ch]) {
hash[ch]--;
if (hash[ch] < 0) return false;
} else return false;
}
for (const count of Object.values(hash)) {
if (count > 0) return false;
}
return true;
};
复杂度
- 时间:m + n;
- 空间:S;
找到字符串中所有字母异位词
题目
- 438;
思路
- 使用哈希表记录 s 和 p 的字母频数;
- 维护固定滑动窗口,记录 s 窗口内的字母频数;
- 判断 sHash 和 pHash 字母频数是否一致;
/**
* @param {string} s
* @param {string} p
* @return {number[]}
*/
var findAnagrams = function (s, p) {
const check = () => {
for (const [key, count] of Object.entries(pHash)) {
if (count !== sHash[key]) return false;
}
return true;
};
const pHash = {};
for (const ch of p) {
if (pHash[ch] != null) pHash[ch]++;
else pHash[ch] = 0;
}
const res = [];
const sHash = {};
let left = 0;
let right = 0;
while (right < s.length) {
if (sHash[s[right]] != null) sHash[s[right]]++;
else sHash[s[right]] = 0;
if (right - left + 1 < p.length) {
right++;
continue;
}
if (check()) res.push(left);
sHash[s[left]]--;
left++;
right++;
}
return res;
};
复杂度
- 时间:n;
- 空间:n;
数组中的重复数据
题目
- 442;
思路
- 由于数组元素范围为 1-n,所以采用原地哈希的思想;
- 对于 num,其目标索引为 num-1;
- 如果目标元素大于 0,说明是第一次访问,将其转换为相反数;
- 这样对其取绝对值就能恢复原始值;
- 如果目标元素小于 0,说明是第二次访问,添加至结果;
/**
* @param {number[]} nums
* @return {number[]}
*/
var findDuplicates = function (nums) {
const n = nums.length;
const res = [];
for (let i = 0; i < n; i++) {
const num = Math.abs(nums[i]);
const targetIndex = num - 1;
if (nums[targetIndex] > 0) {
nums[targetIndex] = -nums[targetIndex];
} else {
res.push(num);
}
}
return res;
};
复杂度
- 时间:n;
- 空间:1;
文物朝代判断
题目
思路
- 遍历 5 个文物;
- 由于 0 是任意朝代,所以忽略;
- 判断 5 个文物是否有重复值,有直接 false;
- 判断 5 个文物取值范围是否大于 4,有直接 false;
- 其余情况返回 true;
/**
* @param {number[]} places
* @return {boolean}
*/
var checkDynasty = function (places) {
const hash = new Set();
let min = 14;
let max = -1;
for (let i = 0; i < 5; i++) {
if (places[i] === 0) continue;
if (hash.has(places[i])) return false;
hash.add(places[i]);
min = Math.min(min, places[i]);
max = Math.max(max, places[i]);
}
if (max - min > 4) return false;
return true;
};
复杂度
- 时间:n;
- 空间:n;
至少有 K 个重复字符的最长子串
题目
- 395;
思路
- 使用哈希表统计字符串各字符频数;
- 如果频数小于 k,说明结果必不可能包括对应字符 ch;
- 将 str 使用 ch 进行分割,对分割后的字符进行递归判断;
/**
* @param {string} s
* @param {number} k
* @return {number}
*/
var longestSubstring = function (s, k) {
if (s.length < k) return 0;
const hash = {};
for (const ch of s) {
if (hash[ch] == null) hash[ch] = 1;
else hash[ch]++;
}
for (const [key, value] of Object.entries(hash)) {
if (value < k) {
let count = 0;
for (const sub of s.split(key)) {
count = Math.max(longestSubstring(sub, k), count);
}
return count;
}
}
return s.length;
};
复杂度
- 时间:n2;
- 空间:n;